Analysis of the OLMo Training Framework: A Commitment to Truly Open Science
Mustafa Mehmood
6/25/202513 min read
Mustafa Mehmood
Introduction
As LLMs’ commercial importance has surged, the most powerful models have become "closed off,” gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. In direct response to this trend, the Allen Institute for AI (AI2) started the OLMo (Open Language Model) project. Guiding every aspect of the project's development and release is the core principle that "the science of language models demands openness."
A distinction must be drawn between the prevailing "open-weight" models like Llama and OLMo's commitment to being "truly open". While many organizations release model weights and inference code, this level of access provides only a partial view of the system. AI2 contends that true scientific progress requires full transparency. The OLMo framework offers insight into its entire development process. This includes the multi-trillion-token training datasets, the training and evaluation code, all model weights, comprehensive intermediate checkpoints saved at least every 1000 training steps, and detailed training logs. This extreme transparency is a conscious decision to tackle the "black-box issue," which has historically hindered verifiable advancements in AI safety, reproducibility, bias mitigation, and innovation.
The OLMo project, "by scientists, for scientists," aims to empower academic and research communities to study language models. Its open framework seeks to drive new scientific inquiry into AI's fundamental questions, including data-model relationships, bias, and risks. This open science approach counters AI's commercialization, proving it can rival proprietary systems while fostering a deeper, more accountable understanding of these powerful technologies.
Section 1: Architectural Blueprint
At their core, all models within the OLMo family are built upon the well-established decoder-only transformer architecture. This design, popularized by the GPT series and now a de facto standard for large-scale autoregressive language models, serves as the foundation upon which AI2 has integrated a curated set of modern architectural components and optimizations.
Key Architectural Choices
The OLMo architecture represents a pragmatic consolidation of established best practices in model design, drawing inspiration particularly from models such as PaLM and Llama. These decisions prioritize maximizing throughput and improving training stability, which are crucial for large-scale, expensive training runs. Key components of the architecture include:
No Bias Terms: Following the precedent set by other major LLMs, all bias terms are excluded from the model's linear layers and attention mechanisms. This simplification has been shown to improve training stability without a discernible loss in performance.
SwiGLU Activation Function: The standard ReLU activation function is replaced with the SwiGLU (Swish-Gated Linear Unit) activation. The hidden size of the feed-forward network's activation is set to approximately 8/3 times the model's hidden dimension (d), a ratio also adopted from Llama. For computational efficiency, this dimension is then increased to the nearest multiple of 128. For example, the 7B model uses a hidden activation size of 11,008.
Rotary Positional Embeddings (RoPE): Instead of using absolute or learned positional embeddings, OLMo incorporates Rotary Positional Embeddings. RoPE has become the standard for modern LLMs due to its ability to effectively encode relative positional information in a way that is flexible to varying sequence lengths.
Tokenizer: The models employ a Byte-Pair Encoding (BPE) based tokenizer that is a modified version of the one used for GPT-NeoX-20B. It includes additional special tokens for masking personally identifiable information (PII). The final vocabulary size is 50,280. To maximize training throughput on modern hardware, the corresponding embedding matrix in the model is padded to a size of 50,304, which is a multiple of 128.
The Layer Normalization Strategy
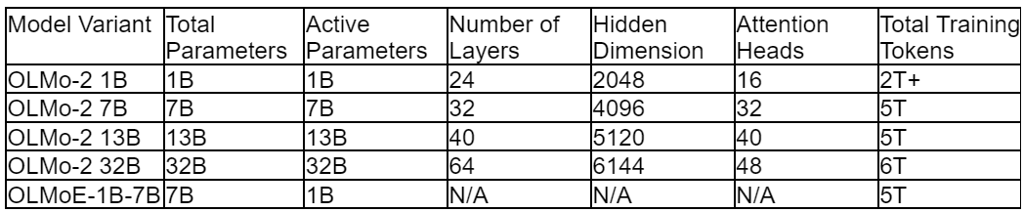
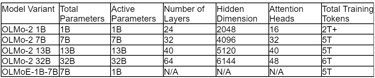
AI2’s OLMoE introduced the first Mixture-of-Experts (MoE) model in the OLMo family, optimizing for performance-to-cost efficiency. For instance, OLMoE-1B-7B had 7 billion parameters but only activated 1 billion per input, enabling roughly twice the training speed of a 7B dense model while retaining the capacity benefits of a larger model. This open-source release (data, code, logs) was a crucial resource for studying sparse expert models.
Table 1: Specifications for select models in the OLMo family. Note: N/A indicates data not specified for the MoE variant.
Section 2: Data Foundation
The OLMo project approaches data curation with a scientific rigor, openly releasing its training corpora and tools. This sets a new benchmark for data transparency and reproducibility in large-scale AI.
Dolma: A Multi-Trillion Token Open Corpus for broad data exposure
Dolma, the foundational pre-training dataset for OLMo models, is a massive and diverse corpus of over 3 trillion English tokens. Its strategic composition aims to provide broad world knowledge and linguistic capability, drawing from:
Web Content: Processed Common Crawl dumps.
Academic Publications: From the S2ORC dataset.
Code: From The Stack dataset.
Books: Public domain texts from Project Gutenberg.
Encyclopedic Materials: Content from Wikipedia and Wikibooks.
AI2 not only released the dataset but also open-sourced the Dolma Toolkit, a high-performance Python-based software for data curation. This toolkit supports parallelism, language and quality filtering, safety-oriented content filtering, fast document deduplication via Rust-based Bloom filters, and includes a suite of pre-built taggers. Releasing this toolkit ensures full reproducibility of the data pipeline, enabling researchers to validate, critique, and extend the data curation methodologies.
The dataset is versioned and managed like a software project. Iterative improvements, such as the evolution to Dolma 1.7, involved incorporating more diverse sources (e.g., Refined Web, StarCoder, OpenWebMath), implementing stricter quality filters, and applying fuzzy deduplication. These data improvements directly led to significant performance gains in the trained models, reinforcing the principle that advances in language models are intrinsically linked to data curation.
Dolmino-mix-1124: The "Annealing" Dataset
The Dolmino-mix-1124 dataset is a specialized, high-quality corpus curated for the
second, shorter "annealing" phase of training. Its purpose is to imbue the model with targeted knowledge and to rectify capability deficits, particularly in complex reasoning domains such as mathematics, that may have been identified during the initial, broader pre-training phase.
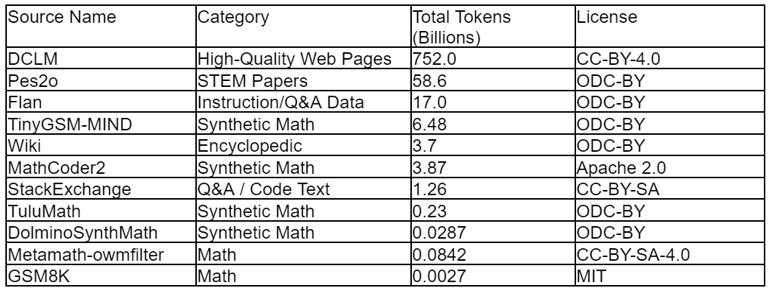
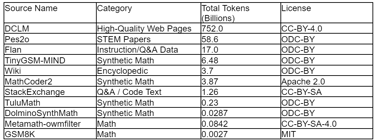
Comprising 843 billion tokens, Dolmino-mix-1124 is a deliberate fusion of high-quality documents from the general corpus and curated, domain-specific sources. Smaller subsets (e.g., 50B, 100B, 300B tokens) are sampled for training. The standard blend for these subsets is an equal split by token count between high-quality web data and specialized content. The specialized component encompasses:
STEM Papers from Pes2o.
Instruction-following data from the Flan collection.
Q&A forum data from StackExchange.
Diverse mathematics data, both human-generated and synthetic, from sources including TuluMath, GSM8K, MathCoder2, and Metamath.
Table 2: Composition of the full Dolmino-mix-1124 data collection, from which smaller training mixtures are sampled. Data sourced from.
Section 3: The Multi-Stage Training Regimen
The training of OLMo models is not a monolithic process but a multi-stage curriculum designed to efficiently build foundational knowledge and then refine specific capabilities. This process treats the initial training as both a knowledge absorption exercise and a large-scale diagnostic test, with the second stage acting as a targeted treatment for identified weaknesses.
Stage 1: Foundational Pre-training
This initial stage consumes the majority of the training budget (90% or more of total computational FLOPs). The model is trained on vast, diverse datasets like OLMo-mix-1124 (3.9 trillion tokens) or Dolma 1.7 (2.3 trillion tokens). The token count ranges from 2 trillion for the 1B model to 6 trillion for the 32B model. The goal is to establish robust linguistic understanding and a broad base of world knowledge. A cosine learning rate schedule is typically used, with a warm-up followed by a long decay. This stage concludes before the learning rate reaches zero, maintaining model plasticity for the next phase.
Stage 2: Mid-Training and Capability "Patching"
This shorter but crucial "mid-training" stage utilizes 5-10% of the total training FLOPs. The training data switches from the broad corpus to the specialized, high-quality Dolmino-mix-1124 dataset. This data shift is specifically designed to "patch" model capabilities and "infuse new knowledge" in areas where Stage 1 evaluations revealed deficiencies, such as mathematical reasoning.
Concurrently with the data switch, the learning rate schedule changes. The learning rate, still relatively high from Stage 1, is linearly annealed to zero over this shorter training phase. This combination of high-quality data and gradual learning rate decay enables effective and stable fine-tuning of the model's knowledge base and reasoning pathways. This responsive, two-stage "Train -> Diagnose -> Treat" process is a more capital-efficient and strategically sound approach than attempting to create a single, perfect multi-trillion token dataset upfront, acknowledging the practical challenges of such a task.
Checkpoint Averaging: The "Model Souping" Technique
To further enhance model robustness and generalization, AI2 employs "model souping" at the conclusion of the mid-training stage. Instead of a single Stage 2 run, it's executed multiple times in parallel. Each run begins from the same final Stage 1 checkpoint but uses a different random shuffling of the same Dolmino-mix tokens. For the 7B model, this involved three runs on a 50B token mix. For the larger 13B and 32B models, it involved three runs on a 100B token mix and one run on a 300B token mix.
After these parallel runs, the weights of the resulting final checkpoints are arithmetically averaged to create the final, single base model. This technique has been shown to find solutions in broader, flatter minima of the loss landscape, which typically corresponds to models with improved robustness and performance across a wide range of downstream tasks.
Section 4: The Post-Training Pipeline: From Base Model to Conversational Agent
A base pre-trained model, while possessing immense knowledge, is fundamentally a next-token predictor; it is not inherently capable of following user instructions or engaging in coherent dialogue. To transform the powerful base OLMo models into helpful and harmless conversational agents, known as OLMo-Instruct (instruction-finetuned OLMo), AI2 employs a multi-stage post-training alignment pipeline. This process is designed to align the model's behavior with human intent and conversational norms.
The OLMo-Instruct models are created using a state-of-the-art methodology adapted from AI2's own Tülu 3 recipe, which has proven highly effective for instruction tuning. This recipe consists of a sequence of fine-tuning stages, each designed to impart a different aspect of conversational ability and preference alignment.
The conversion to instruct-tuned model involves three primary steps:
Supervised Fine-Tuning (SFT): This is the first and most foundational alignment step. The base model is fine-tuned on a large, high-quality dataset of instruction-response pairs. This teaches the model the expected format of an instruction-following interaction (e.g., responding to a question rather than simply completing the text of the question). The dataset used is a carefully curated and filtered version of the Tulu 3 SFT Mixture, with problematic examples (like mentions of a data cutoff date from synthetic generation) removed to improve data quality.
Direct Preference Optimization (DPO): Following SFT, the model's behavior is further refined using a preference dataset. This data consists of prompts, each with a "chosen" (preferred) response and a "rejected" (less preferred) response. By training on this data, the DPO algorithm adjusts the model's internal probabilities to make it more likely to generate responses similar to the chosen ones, effectively steering its output to be more aligned with human preferences for helpfulness and safety without the need for a separate reward model.
Reinforcement Learning with Verifiable Rewards (RLVR): This is the final and most advanced stage of the OLMo alignment pipeline, representing a significant evolution from standard Reinforcement Learning from Human Feedback (RLHF). Instead of relying on a learned reward model, which can be fallible and susceptible to "reward hacking," RLVR focuses on domains where the correctness of an output can be programmatically and objectively verified. For OLMo, RLVR is applied to tasks like grade-school math (GSM8K) and advanced mathematics (MATH), where a final answer can be checked for correctness, and instruction-following tasks (IFEval), where adherence to constraints can be verified. This provides a "gold-standard," non-gameable reward signal, rewarding the model for generating verifiably correct reasoning and outputs. This strategic choice to ground reinforcement learning in objective truth robustly improves the model's factuality and complex reasoning capabilities, mitigating a key failure mode of traditional RLHF.
Section 5: Infrastructure, Software, and Efficiency
Developing advanced language models requires strong software, systems engineering, and AI modeling. The OLMo project leveraged powerful hardware, custom software, and a focus on efficiency.
Hardware: The LUMI Supercomputer
Large-scale OLMo model training was done on the LUMI supercomputer in Finland, a collaboration with CSC. At the time, LUMI was Europe's most powerful and a global top-five supercomputer, known for its carbon-free energy use.
LUMI, an HPE Cray EX, all-AMD system, has a critical GPU partition with thousands of nodes, each having a 64-core AMD EPYC CPU and four AMD Instinct MI250X GPUs. This partnership provided the computing power for training models with billions of parameters on trillions of tokens.
For its more recent and larger models, such as the OLMo 2 32B, AI2 turned to the cloud and utilized a massive NVIDIA-powered infrastructure. This state-of-the-art model was trained on "Augusta," a 160-node AI Hypercomputer provided by Google Cloud. Each node in this cluster is outfitted with eight NVIDIA H100 GPUs, interconnected with GPUDirect-TCPXO for high-speed communication between the processors. This formidable setup highlights the immense computational resources required to train leading-edge large language models.
Software Stack: OLMo-core and PyTorch FSDP
AI2 developed OLMo-core, a new, custom training codebase for large models like OLMo 2 32B, to efficiently leverage LUMI. Built on PyTorch and FSDP, OLMo-core supports distributed training by sharding model parameters, gradients, and optimizer states across GPUs. This reduces memory footprint, enabling larger model training. The OLMo GitHub repository offers the complete training code, configuration files, and Docker images for replication.
Engineering for Efficiency
A key theme of the OLMo project is computational efficiency. The OLMo 2 32B model, for instance, was trained using only one-third of the compute (measured in FLOPs) as comparable open-weight models, while achieving competitive or superior performance. This was accomplished through dedicated software engineering efforts that yielded significant throughput improvements. Specific optimizations included:
Asynchronous Checkpointing: AI2 implemented asynchronous checkpointing using PyTorch's save_state_dict_async API. This allows the process of saving a model checkpoint to occur in parallel with the ongoing training loop, rather than pausing it. This effectively minimizes training downtime and maximizes GPU utilization.
Minimal Host-Device Synchronization: Reducing the number of synchronization points between the host CPU and the GPU devices is critical for maintaining high throughput. The OLMo-core framework was optimized to minimize these syncs.
PyTorch Optimizations: Through careful profiling and code optimization, the team achieved an overall throughput improvement of 30% in the OLMo-core framework.
Open-sourcing both the model and its high-performance "kitchen", AI2 makes large-scale AI research more accessible and sustainable.
Section 6: The Ecosystem for Open Science
The OLMo project extends beyond the model itself, encompassing a suite of tools and resources that transform it from a static artifact into a dynamic, interactive laboratory for studying the fundamental properties of LLMs. This ecosystem is the ultimate expression of the project's "by scientists, for scientists" philosophy.
OLMoTrace
OLMoTrace, a groundbreaking tool, is a key component of the OLMo ecosystem. It offers a unique ability to trace a model's generated output in real-time, linking it directly to exact text matches found within its vast multi-trillion-token training corpus.
This capability is only possible because the training data is fully open and indexed. When a user queries the model in the AI2 Playground, they can activate OLMoTrace, which highlights segments of the response and displays up to 10 document snippets from the training data that contain the exact same text.
This tool directly confronts the "black box" problem and has profound implications for AI accountability. It enables a new paradigm of empirical auditing, allowing users to:
Fact-Check Claims: If a model makes a factual statement, a user can trace it to its source documents and verify their reliability.
Investigate Memorization: Users can determine if a "creative" or novel-sounding phrase was genuinely generated or simply memorized from the training data.
Audit for Bias and Safety: Researchers can trace problematic or biased outputs to their specific origins within the data, providing a direct link between training data and model behavior that is impossible to establish with closed models.
OLMoTrace shifts the paradigm of AI trust from a reliance on developer promises to a system based on verifiable, empirical evidence, enabling a new class of scientific research into the inner workings of LLMs.
Supporting Tools for Data and Evaluation
To support the full research lifecycle, AI2 has released a collection of open-source tools for data curation and model evaluation:
Dolma Toolkit: As detailed previously, this high-performance toolkit for data curation enables the full replication and extension of the OLMo pre-training dataset, promoting transparent and reproducible data science.
olmOCR: To help unlock new data sources for future models, AI2 developed olmOCR, an open-source Python toolkit for processing PDFs. It uses a fine-tuned 7B parameter Vision Language Model to convert scanned documents into clean, structured text, preserving elements like tables, lists, and equations. The entire system including VLM weights, data, and code is open-sourced.
Open Evaluation Suite: In line with its commitment to reproducibility, AI2 provides the complete code and data used to generate its benchmark results. This allows for independent verification and scrutiny of its performance claims. The evaluation framework builds on existing tools like Catwalk and includes AI2's custom Open Language Modeling Evaluation System (OLMES), a suite of 20 benchmarks designed to provide a high signal-to-noise ratio for assessing model improvements during development.
Conclusion: The Impact and Future of Truly Open Language Models
The OLMo project is a major step forward in AI, proving that top performance and full transparency can go hand in hand. AI2 has released everything from models, data, code, and tools to offering a complete guide for open and scientifically sound AI development.
The project's success rests on five pillars. First is the philosophical commitment to being "truly open," which directly challenges the industry trend toward secrecy and provides the foundation for verifiable research. Second is the meticulously curated and fully open data corpora, Dolma and Dolmino, coupled with the tools to reproduce them, elevating data curation to a transparent science. Third is the sophisticated, multi-stage training curriculum, which employs a responsive "diagnose and treat" methodology to efficiently patch model capabilities. Fourth is the high-performance systems engineering, embodied in the OLMo-core framework, which proves that computational efficiency can be a decisive advantage. Finally, the ecosystem of tools, headlined by the revolutionary OLMoTrace, transforms the model into an interactive laboratory for unprecedented scientific inquiry into AI behavior.
By offering this entire framework under a permissive license, OLMo makes large-scale AI research more accessible globally. It challenges the idea that cutting-edge progress requires proprietary development, promoting collaboration and shared knowledge. OLMo is not just releasing models; it's shaping a more transparent future for AI science, empowering a global community to build and understand these technologies together.
References.
OLMo: Accelerating the Science of Language Models, https://arxiv.org/abs/2402.00838
Paper page - OLMo: Accelerating the Science of Language Models - Hugging Face, https://huggingface.co/papers/2402.00838
Ai2 Pushes For Open-Source AI with OLMo 2 32B - AI-Pro.org, https://ai-pro.org/learn-ai/articles/ai2-opens-new-possibilities-with-olmo-2-32b/
OLMo : Accelerating the Science of Language Models - ACL Anthology, https://aclanthology.org/2024.acl-long.841.pdf
OLMo from Ai2, https://allenai.org/olmo
Language models | Ai2, https://allenai.org/language-models
OLMo : Accelerating the Science of Language Models - arXiv, https://arxiv.org/html/2402.00838v1
allenai/OLMo: Modeling, training, eval, and inference code ... - GitHub, https://github.com/allenai/OLMo
Understanding and Improving Layer Normalization, http://papers.neurips.cc/paper/8689-understanding-and-improving-layer-normalization.pdf
OLMo 2: The best fully open language model to date | Ai2, https://allenai.org/blog/olmo2
OLMoE: Open Mixture-of-Experts Language Models - arXiv, https://arxiv.org/html/2409.02060v1
[2409.02060] OLMoE: Open Mixture-of-Experts Language Models - arXiv, https://arxiv.org/abs/2409.02060
Dolma | Ai2, https://allenai.org/dolma
dolma | Data and tools for generating and inspecting OLMo pre-training data. - GitHub Pages, https://allenai.github.io/dolma/
allenai/dolma · Datasets at Hugging Face, https://huggingface.co/datasets/allenai/dolma
Dolma: An Open Corpus of 3 Trillion Tokens for Language Model Pretraining Research - GitHub Pages, https://allenai.github.io/dolma/docs/assets/dolma-v0_1-20230819.pdf
[2402.00159] Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research - arXiv, https://arxiv.org/abs/2402.00159
OLMo 1.7–7B: A 24 point improvement on MMLU | Ai2, https://allenai.org/blog/olmo-1-7-7b-a-24-point-improvement-on-mmlu-92b43f7d269d
allenai/OLMo-2-0425-1B - Hugging Face, https://huggingface.co/allenai/OLMo-2-0425-1B
DOLMino dataset mix for OLMo2 stage 2 annealing training. - ModelScope, https://modelscope.cn/datasets/allenai/dolmino-mix-1124
allenai/dolmino-mix-1124 · Datasets at Hugging Face, https://huggingface.co/datasets/allenai/dolmino-mix-1124
OLMo 2 32B: First fully open model to outperform GPT 3.5 and GPT 4o mini | Ai2, https://allenai.org/blog/olmo2-32B
allenai/OLMo-7B-0724-hf - Hugging Face, https://huggingface.co/allenai/OLMo-7B-0724-hf
Basics of Instruction Tuning with OLMo 1B - MLOps Community, https://mlops.community/basics-of-instruction-tuning-with-olmo-1b/
[2501.00656] 2 OLMo 2 Furious - arXiv, https://arxiv.org/abs/2501.00656
Going beyond open data – increasing transparency and trust in language models with OLMoTrace | Ai2, https://allenai.org/blog/olmotrace
LUMI part of AI2 OLMo, an open language model made by scientists ..., https://www.lumi-supercomputer.eu/ai2-olmo-an-open-language-model-made-by-scientists-for-scientists/
Hello OLMo: A truly open LLM - Ai2, https://allenai.org/blog/hello-olmo-a-truly-open-llm-43f7e7359222
LUMI - The Most Powerful Supercomputer In Europe - Silicon UK, https://www.silicon.co.uk/e-innovation/lumi-the-most-powerful-supercomputer-in-europe-579392
AMD-Powered LUMI Supercomputer: In the Vanguard of HPC Performance and Energy Efficiency - insideHPC, https://insidehpc.com/2023/05/amd-powered-lumi-supercomputer-in-the-vanguard-of-hpc-performane-and-energy-efficiency/
Pretraining an OLMo model with PyTorch FSDP - ROCm Documentation - AMD, https://rocm.docs.amd.com/projects/ai-developer-hub/en/latest/notebooks/pretrain/torch_fsdp.html
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens - arXiv, https://arxiv.org/abs/2504.07096
[2502.18443] olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models, https://arxiv.org/abs/2502.18443